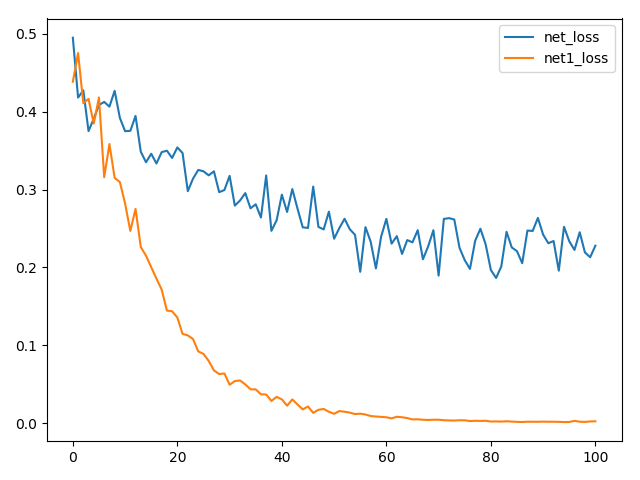
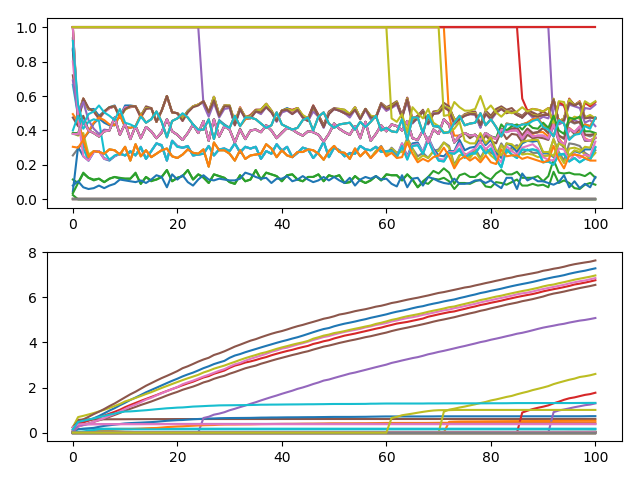
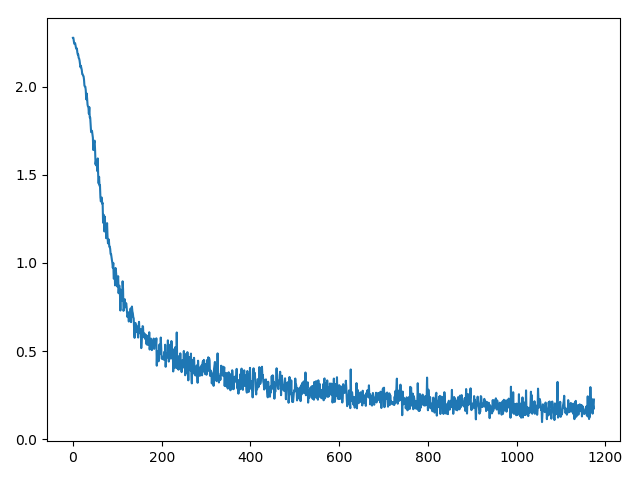
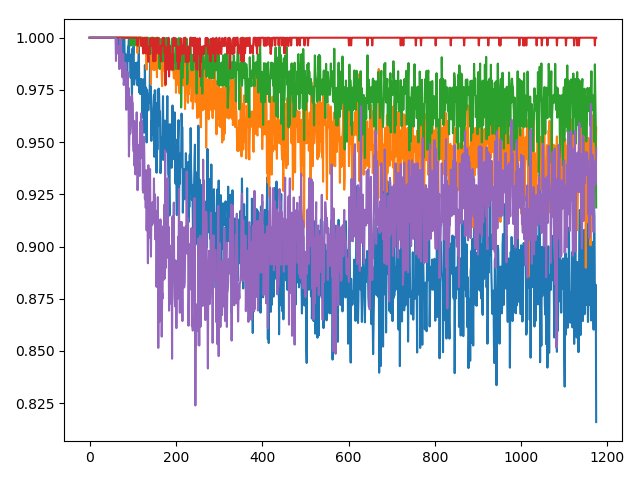
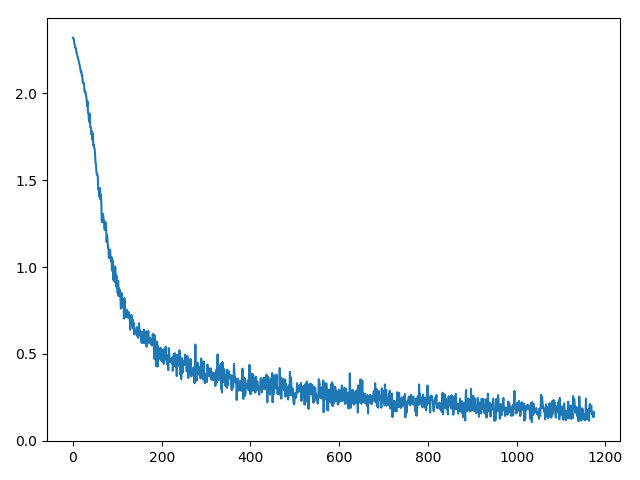
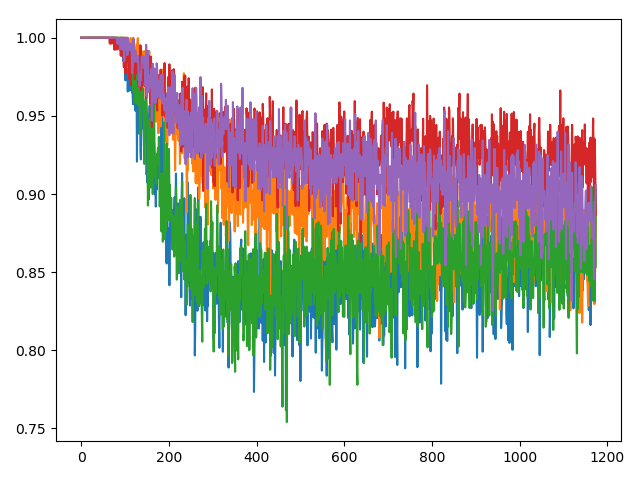
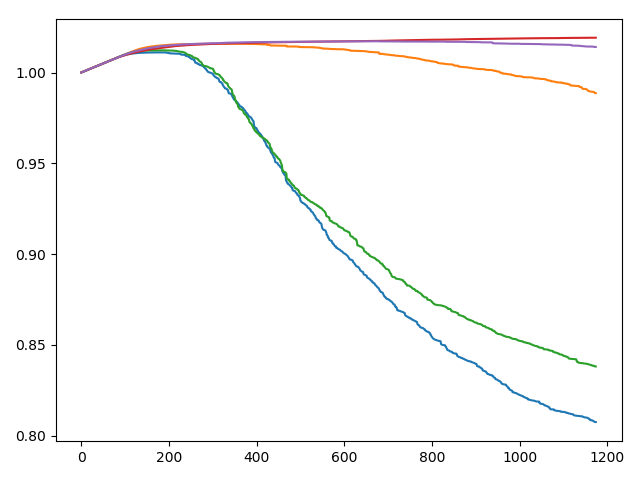
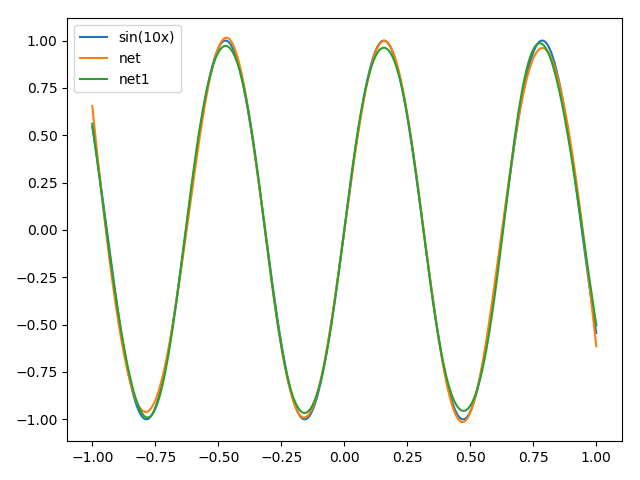
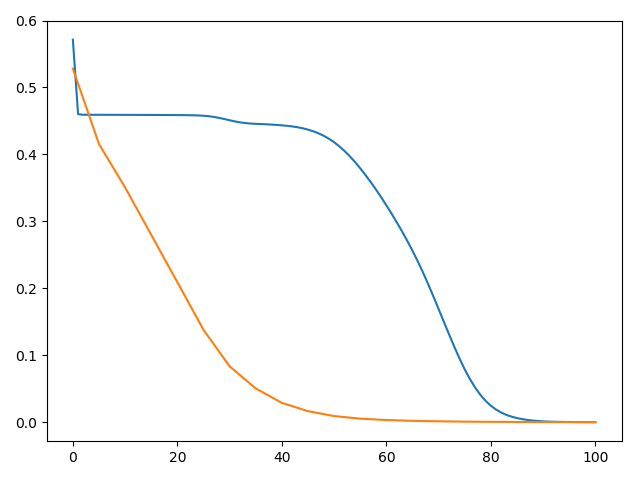
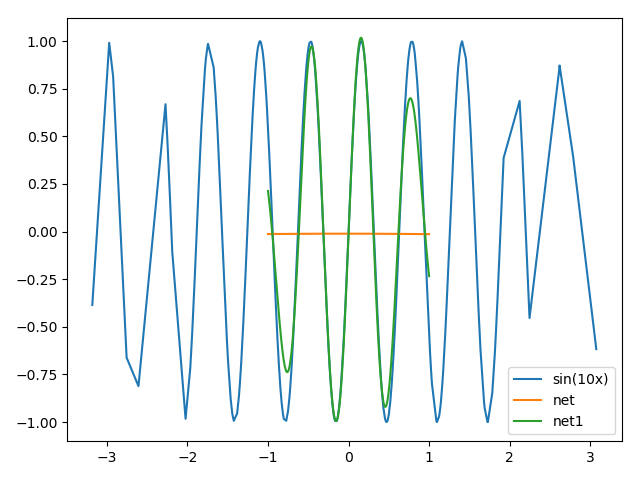
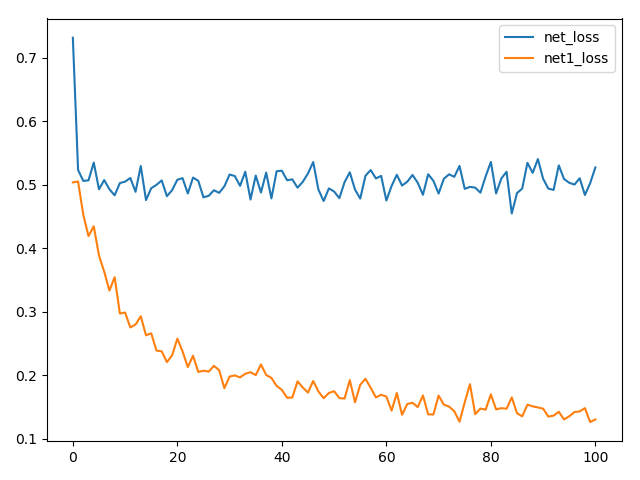
数据集
HAR
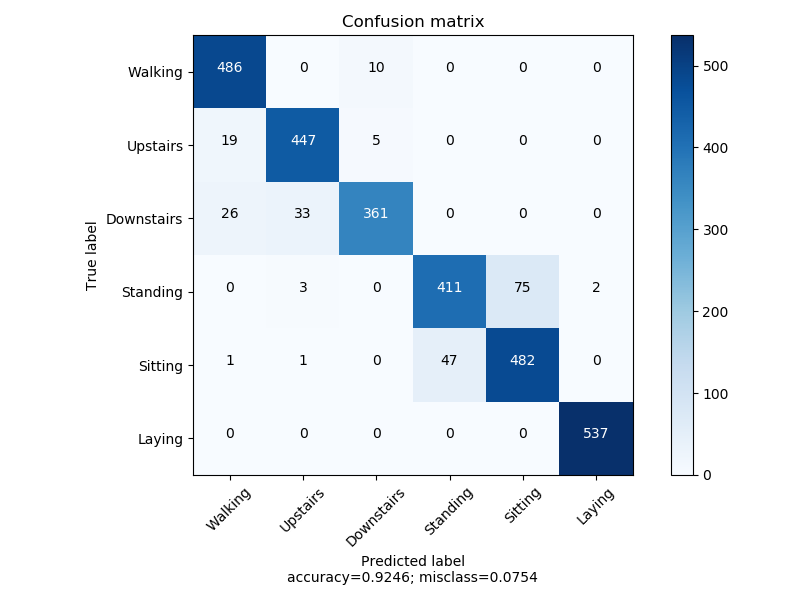
该数据集包含561个特征,拥有6个分类.共10299条数据. 利用智能手机,通过加速度计和陀螺仪,以50HZ的频率采样得到3维的加速度和角速度信息.
LogisticRegression
SVM
相关论文使用SVM做分类器.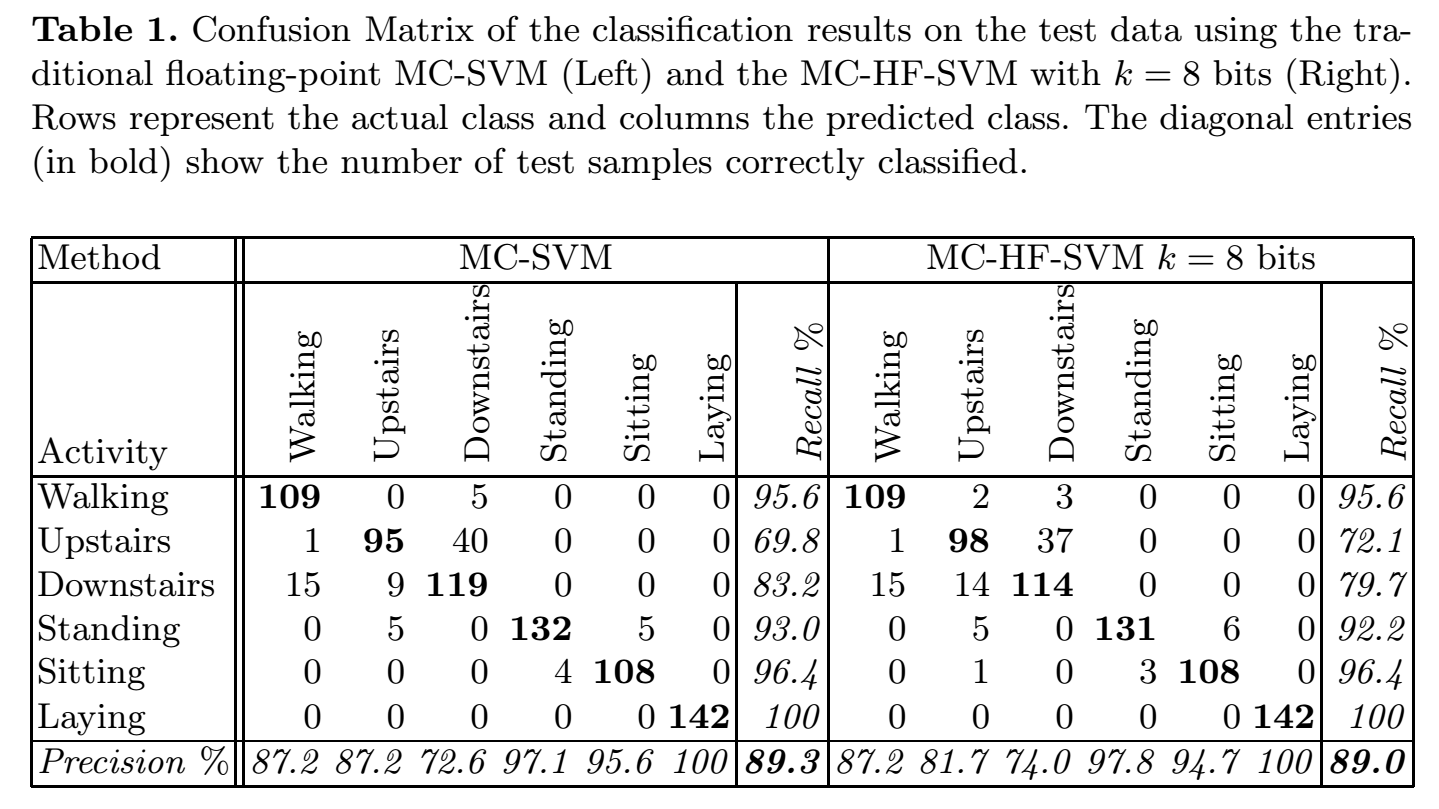
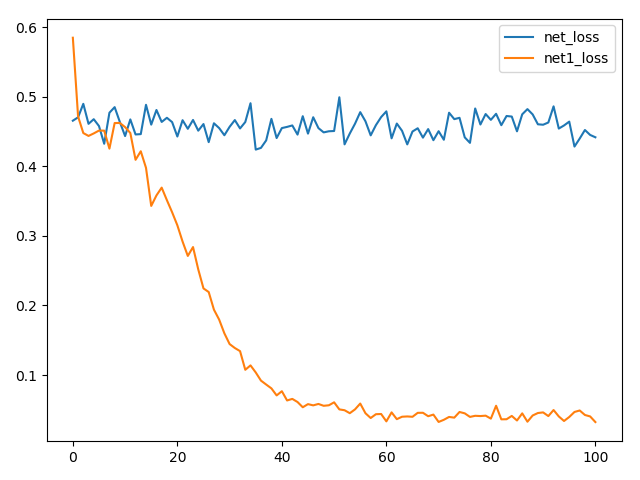
单隐层
结构
Sequential(
(0): Linear(in_features=561, out_features=600, bias=True)
(1): Sigmoid()
(2): Linear(in_features=600, out_features=6, bias=True)
)
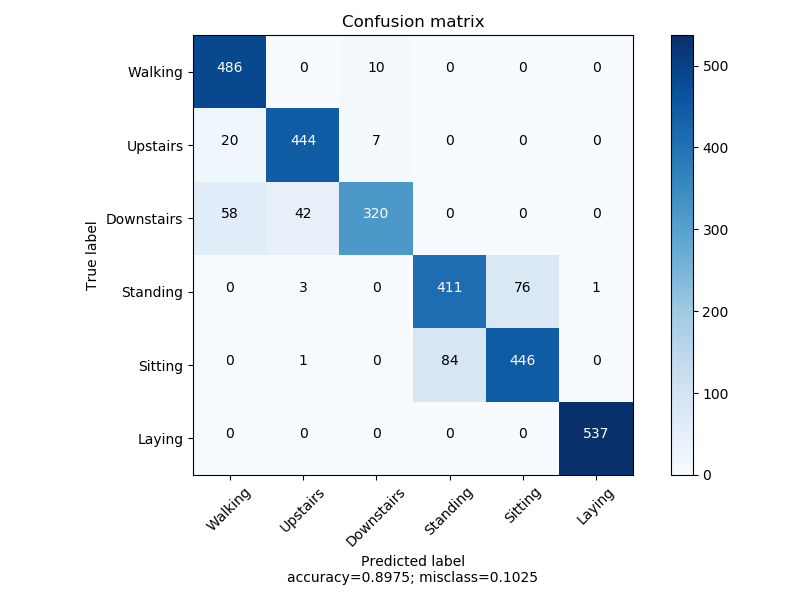
结构
Sequential(
(0): Linear(in_features=561, out_features=600, bias=True)
(1): Tanh()
(2): Linear(in_features=600, out_features=6, bias=True)
)
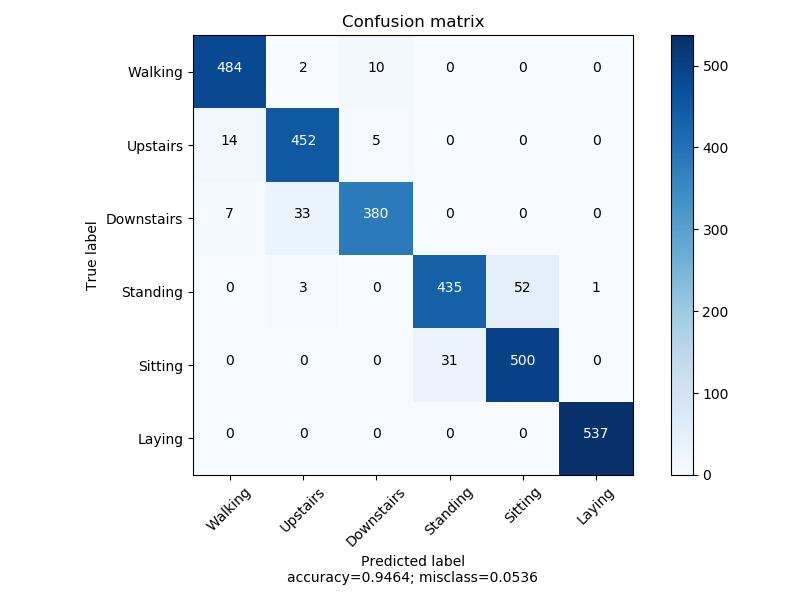
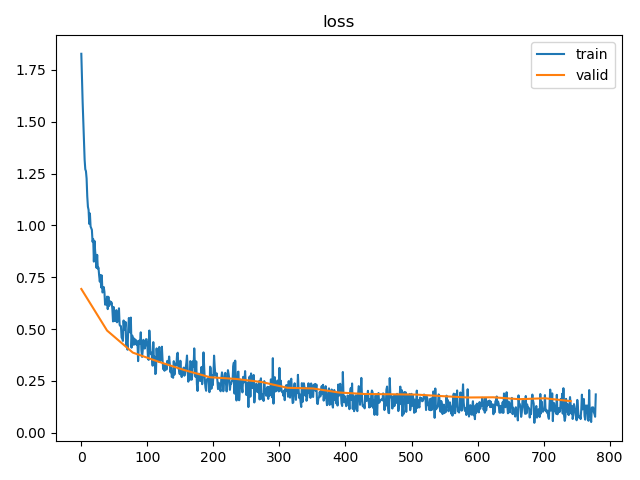
结构
Sequential(
(0): Linear(in_features=561, out_features=600, bias=True)
(1): ReLU()
(2): Linear(in_features=600, out_features=6, bias=True)
)
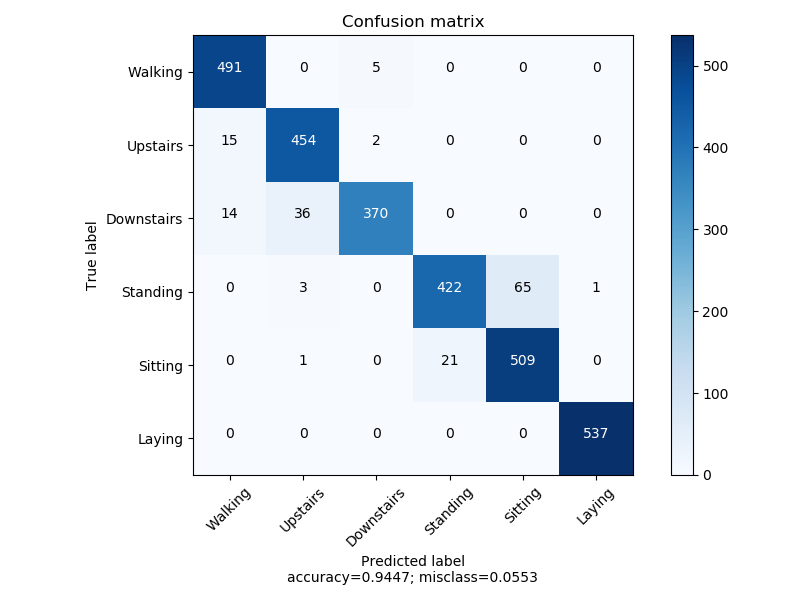
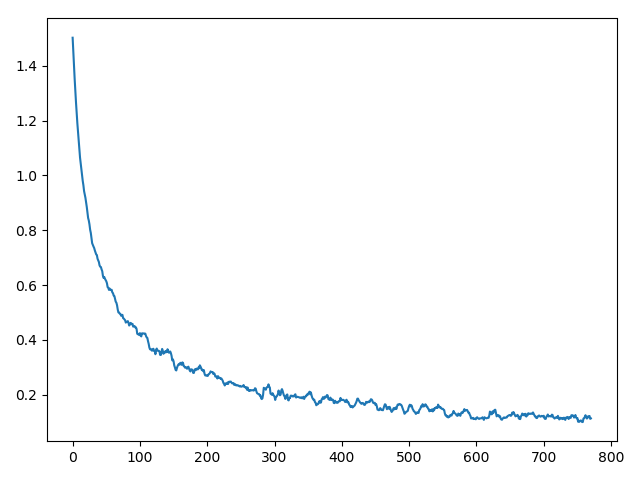
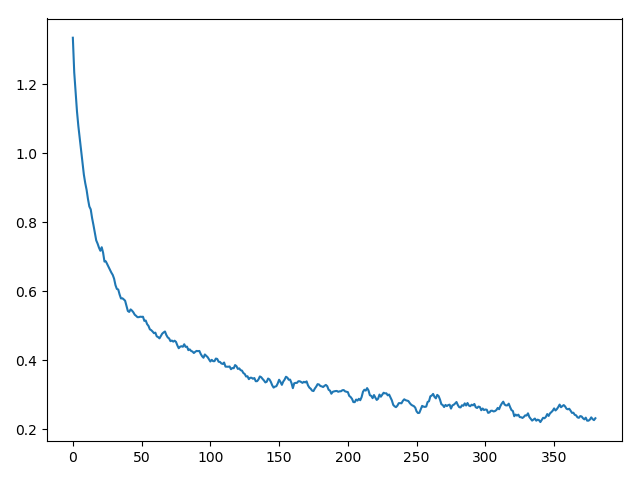
KSelection
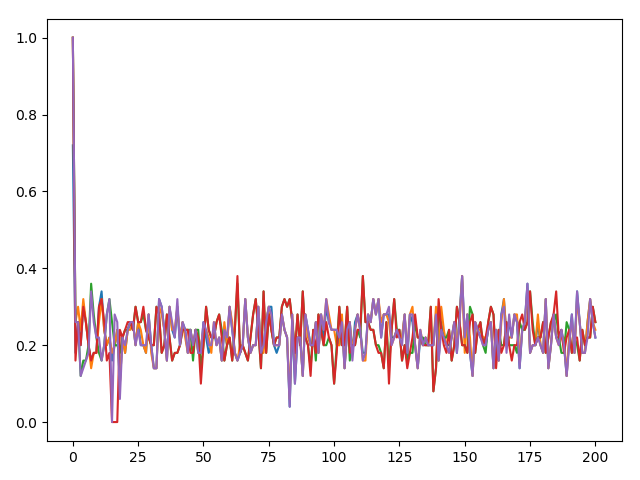
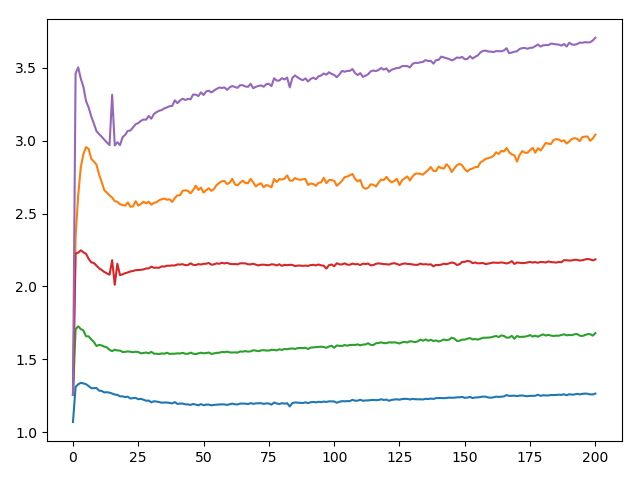
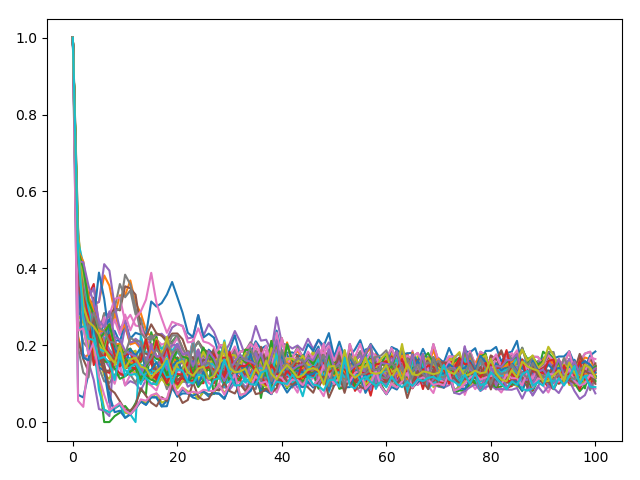
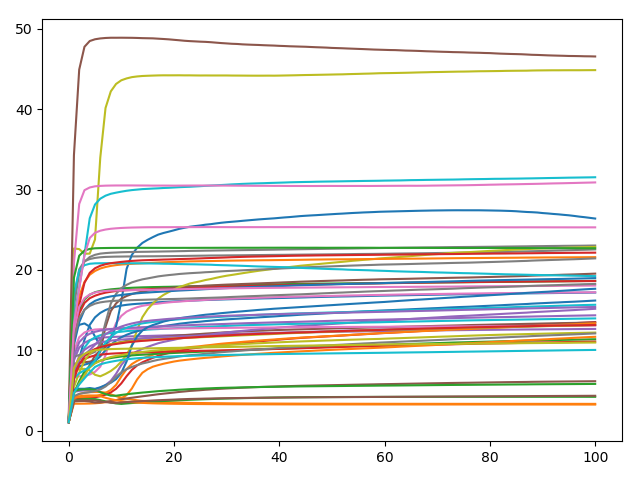
首先分析数据的分布情况.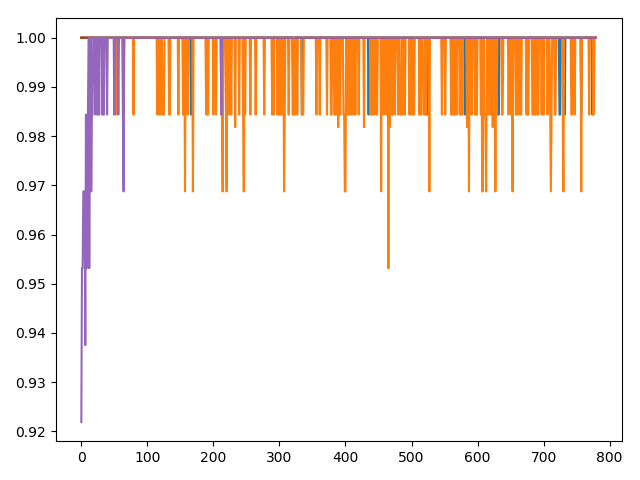
平均占比也有0.98.且采用logistic regression也取得了不错的结果.由此可见有很大一块区域为线性的.
首先使用d=0.2的KTanh做尝试.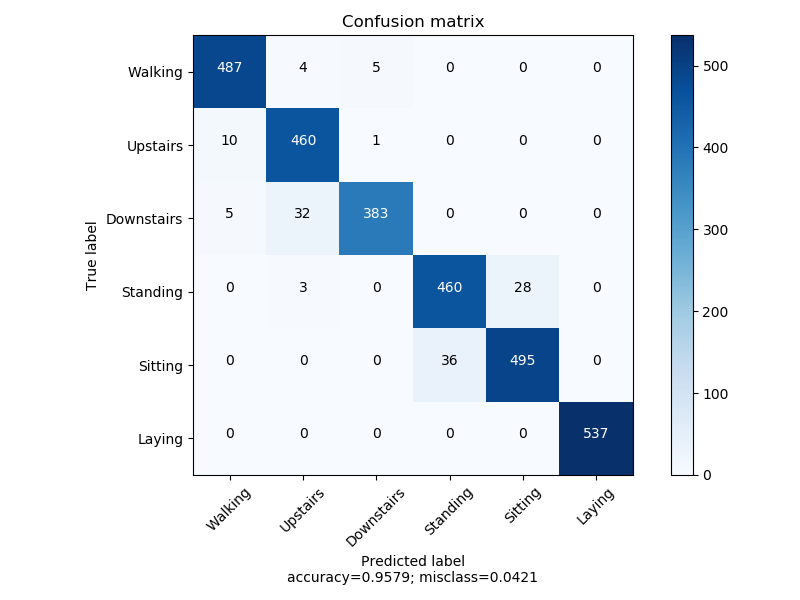
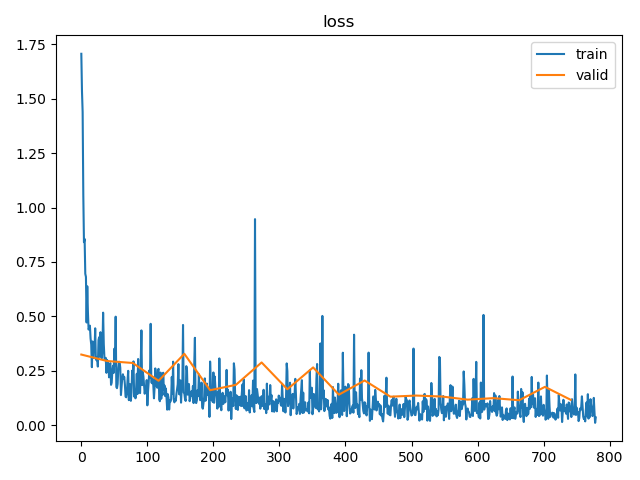
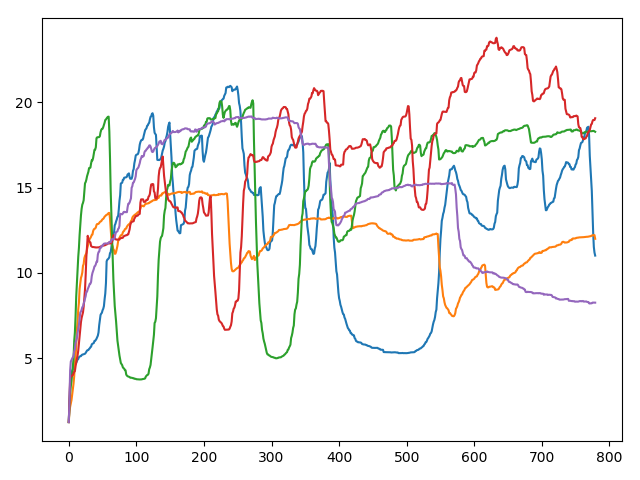
问题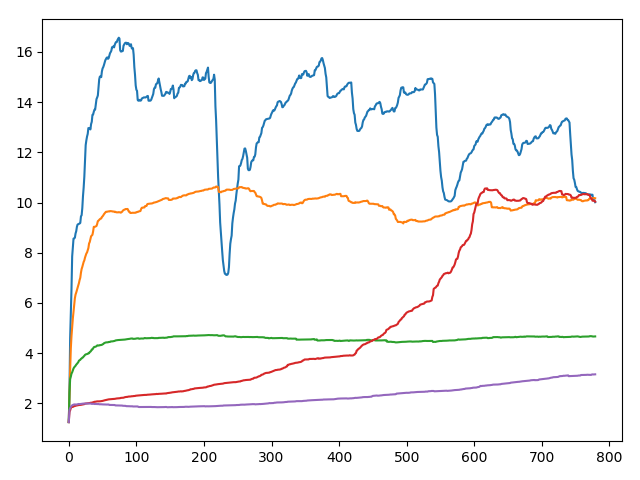
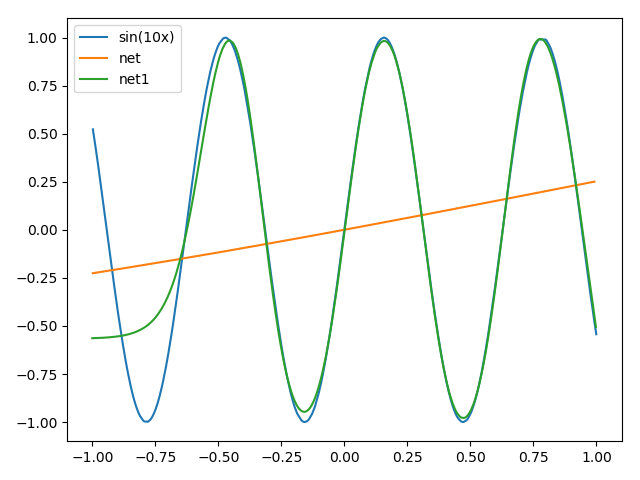
而在简单任务(sin x)的学习中的: