GDT 的结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/* segment descriptors */
struct segdesc {
unsigned sd_lim_15_0 : 16; // low bits of segment limit
unsigned sd_base_15_0 : 16; // low bits of segment base address
unsigned sd_base_23_16 : 8; // middle bits of segment base address
unsigned sd_type : 4; // segment type (see STS_ constants)
unsigned sd_s : 1; // 0 = system, 1 = application
unsigned sd_dpl : 2; // descriptor Privilege Level
unsigned sd_p : 1; // present
unsigned sd_lim_19_16 : 4; // high bits of segment limit
unsigned sd_avl : 1; // unused (available for software use)
unsigned sd_rsv1 : 1; // reserved
unsigned sd_db : 1; // 0 = 16-bit segment, 1 = 32-bit segment
unsigned sd_g : 1; // granularity: limit scaled by 4K when set
unsigned sd_base_31_24 : 8; // high bits of segment base address
};
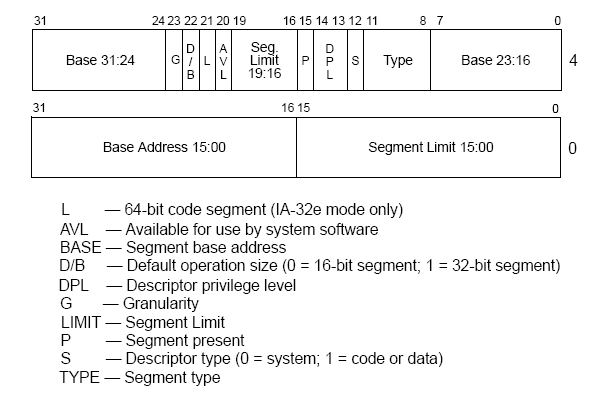
组成:
- 32 位的段基址
- 20 位的段界限
- 1 位的D/B Flag:说明使用16位/32位的段。为1即可。
- 1 位的G(Granularity,粒度):为 1 ,段的大小以 4 KB 为单位。为0,段的大小为1byte。
- 1 位的L:1为64位系统。0为32位。
- 1 位的P(segment-Present,段占用?) : 用于标志段是否在内存中。
- 2 位的DPL:DPL(Descriptor Privilege Level)域标志着段的特权级,0为特权级,3为用户。
- 1 位的S:S(descriptor type) flag 标志着该段是否系统段:置为 0 代表该段是系统段;置为 1 代表该段是代码段或者数据段。
- 4 位的Type:设置数据/代码段时的读写等权限。
- 1位的AVL:保留给操作系统软件使用的位。
共64位。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#define SEG(type, base, lim, dpl) \
(struct segdesc){ \
((lim) >> 12) & 0xffff, (base) & 0xffff, \
((base) >> 16) & 0xff, type, 1, dpl, 1, \
(unsigned)(lim) >> 28, 0, 0, 1, 1, \
(unsigned) (base) >> 24 \
}
/* Application segment type bits */
#define STA_X 0x8 // Executable segment
#define STA_E 0x4 // Expand down (non-executable segments)
#define STA_C 0x4 // Conforming code segment (executable only)
#define STA_W 0x2 // Writeable (non-executable segments)
#define STA_R 0x2 // Readable (executable segments)
#define STA_A 0x1 // Accessed
初始化GDT
1 | |
系统启动时cs为8H,ds为10H.
gdt[x]描述了该段的工作方式。其下标x指名当cs/ds为x<<3时,该描述符生效。
IDT的结构
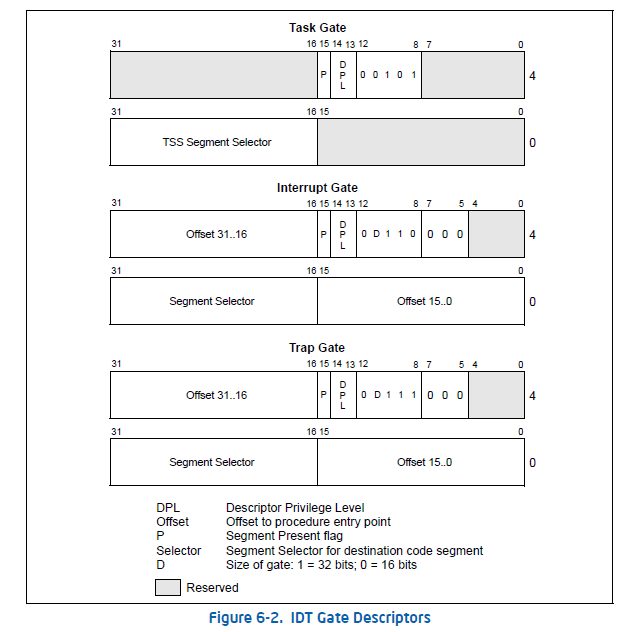
IDT是一个最大为256项的表,每个表项为8字节。称为中断门。CPU通过IDT.base+n*8来寻找门。
1 | |
组成:(陷阱门、中断门)
- 32 位中断地址: 中断服务程序的地址
- 16 位段选择地址:中断服务程序的段地址
- 4 位类型: STS_{TG,IG32,TG32}
- 2 位的DPL:DPL(Descriptor Privilege Level)域标志着中断的特权级,0为特权级,3为用户。
1 | |
初始化
1 | |
